Hai una richiesta specifica? Ti serve uno dei nostri servizi? Vuoi semplicemente conoscerci?
Qualsiasi sia la tua necessità, contattaci e saremo lieti di prendere in carico la tua richiesta.




Il file di Log è un documento indispensabile per chi si occupa di Seo perchè rispecchia l'esperienza di scansione dei Motori di Ricerca sul nostro sito web in un dato intervallo di tempo.
I Log restituiscono dati certi e non si basano esclusivamente su valutazioni personali o di sentimento; l'analisi di questa montagna di dati ci permette di prendere decisioni strategiche e far crescere il nostro business.
Comprendere come migliorare il rapporto con lo Spider rappresenta la continua sfida di ogni sito web che voglia posizionarsi e aumentare le sue opportunità di conversione.
Log File Analysis può aiutare il professionista Seo in 5 step fondamentali durante le sue analisi leggiadre (cit. Leopardi):
1- analizzare quali siano gli elementi che possono o non possono essere “crawlerati” dallo Spider;
2- ottenere il “response code” che viene restituito dal sito web allo Spider e correggere gli errori;
3- identificare degli eventuali “coni di bottiglia” o criticità del sito web in termini di gerarchia della struttura o collegamenti interni ed esterni;
4- scoprire quali siano le pagine o elementi (es. immagini, javascript) che il crawler rileva come importanti e cui riserva una priorità;
5- scoprire quali siano le temutissime “waste area”, aree inutili in cui il sito web esaurisce il proprio Crawling Budget. Eliminare queste aree permetterà allo Spider di scoprire e valorizzare le pagine ed elementi più importanti senza difficoltà ed in minor tempo.
Una volta che abbiamo compreso le potenzialità dell’analisi dei file di log vediamo alcuni spunti per poter trarre il massimo dall’analisi con lo strumento “Log File Analyser” di Screaming Frog.
Sul mercato esistono molti modi per fare un “crawl” di un sito web, attraverso strumenti come Screaming Frog, Google Search Console, Google Analytics o una sitemap in formato xml, ma nessuno di questi metodi ci permette di conoscere con esattezza quali url sono stati richiesti effettivamente dallo Spider durante la sua fase di “crawling”. Per superare questa lacuna il file di log ci viene in aiuto e ci restituisce esattamente quali sono state le pagine che sono state visitate dal Motore di Ricerca.
In Log File Analyser sarà sufficente fare un “drag & drop” del documento di log del server in formato "csv o Excel" e lo strumento verificherà in primis quali Bot hanno fatto accesso al nostro server e in seconda analisi, attraverso la funzione “Verify the Search Engine Bots”, autentificherà i Bot dei principali motori di ricerca (Bingbot, Googlebot, etc) rispetto a Bot mascherati o emulatori (ex. Scansioni con Screaming Frog) chiamati “Spoofed”.
Questa funzione sarà a disposizione sul pannello alla voce “URLs” utilizzando il “Verification Status Filter”.
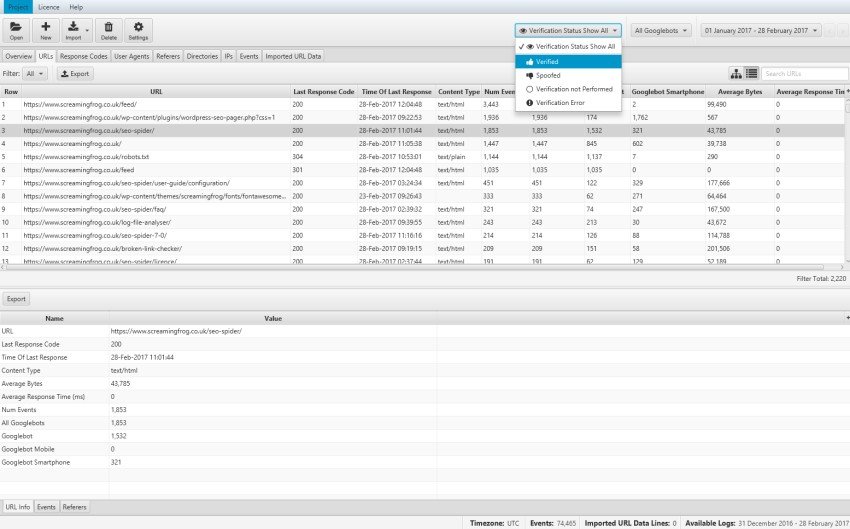
Identificare gli "Urls crawlerati" ci permette di comprendere quali siano le pagine conosciute e già in pancia al motore di ricerca e quali presentino potenziali criticità a livello di indicizzazione.
Inoltre questa funzione permette di verificare se delle pagine caricate attraverso JavaScript vengano viste e analizzate dallo Spider in fase di Crawling.
La conoscenza dei Log diventa poi indispensabile in caso di recente migrazione perché ci mostra quali Urls sono ancora nel database del motore di ricerca e, se le risorse non esistono più, se restituiscono il corretto “status code”.
I file di log ci permettono di conoscere quali sono gli url scansionati dai BOT e quale sia la frequenza di scansione; grazie a queste metriche saremo in grado di scoprire potenziali “Waste areas” dove lo Spider spreca il Crawling Budget. Queste aree potrebbero essere rappresentate da URLs con le sessioni ID, navigazioni a faccette o contenuti duplicati e magari non sono state gestite corretamente con "tag canonical".
In questo caso, se volessimo scoprire delle aree con parametri, possiamo utilizzare il filtro di ricerca ed inserire il simbolo “?”.
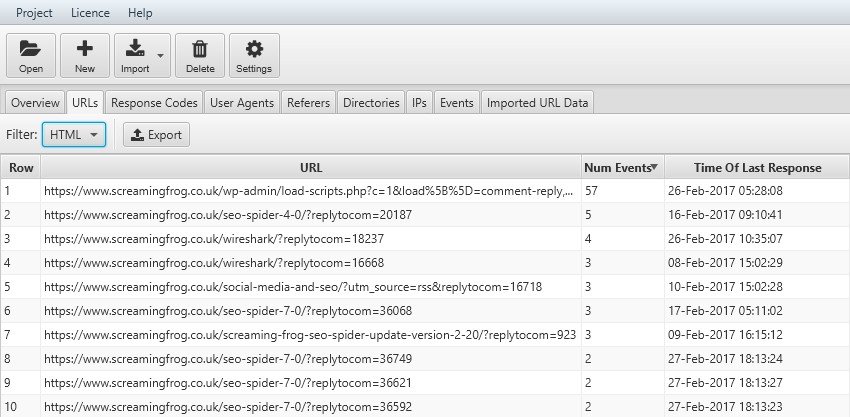
Quando viene progettato un sito web e costruita la Sitemap contestuale si definiscono quali le "top pages" (es. Home, contatti, servizi) e quali saranno delle pagine secondarie. Quello che succede nella realtà però potrebbe essere differente e la nostra visione iniziale potrebbe essere stata interpretata differemìntemente dallo Spider di Google o dagli altri Motori di Ricerca.
Identificare senza indugio quali siano gli url che sono stati “crawlerati” e quale sia la loro frequenza di scansione ci permetterà di comprendere l'autorevolezza assegnata dallo spider ai nostri elementi pubblicati che potrebbe essere differente dalla nostra. In questo contesto potremo gestire eventuali criticità magari aumentando il contenuto di un elemento o declassandone un altro.
Nella scheda “URLs” sarà possibile vedere quanti “eventi” (numero totale di richieste di un url da parte del BOT) sono stati registrati nel file di log su uno specifico elemento e, allo stesso modo, vedere quale BOT ha dato maggiore o minore enfasi nella sua fase di scansione.
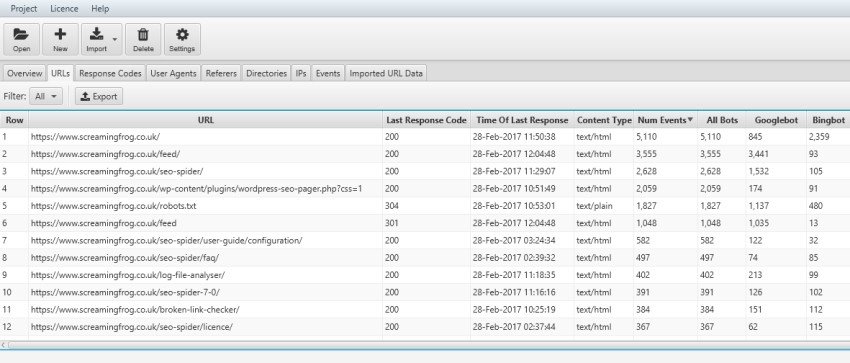
Le varie colonne possono essere ordinate con un click cosicché avremo immediatamente sott’occhio quali elementi hanno ricevuto maggiore attenzione da parte dei Bot e quali pagine siano state ignorate con minori scansioni (events); nel secondo caso se vedessimo degli URLs che riteniamo fondamentali ma con risultati scadenti potremo decidere di cambiare, aggiornare o arricchire il contenuto della pagina per confrontare il prossimo “crawling” del BOT e verificare se la sua considerazione inizia a crescere.
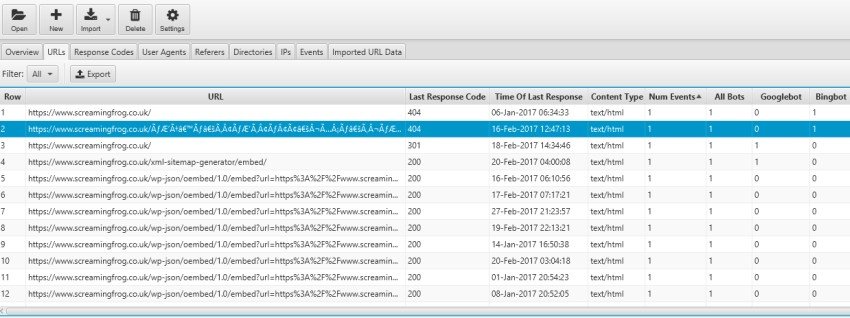
Questa analisi dei file di log ci permette inoltre di scoprire eventuali criticità rispetto alla struttura del sito web, la sua gerarchia, i suoi collegamenti interni o altre informazioni di avvertimento. In questo modo avremo ben chiaro quanto Googlebot, BIngbot, Yandex e gli altri Motori di Ricerca sprechino il loro tempo di crawling per analizzare risorse inutili.
La frequenza di scansione può venire ulteriormente ottimizzata aggregando i “crawl event” per sub-categorie; questo filtro ci permette di conoscere le macro aree che hanno differente rilevanza per i BOT e comprendere se l’area Blog, un particolare autore o la sezione di “servizi” è quella che rappresenta l’essenza per il bot del nostro sito web. Allo stesso tempo ci potrebbe portare a considerare una “Waste Area” e decidere di eliminarla salvaguardando il Crawl Budget del Motore di Ricerca. Scorrendo la tabella di log file analyser sarà molto semplice identificare per singola sub-directory eventuali problemi con status code 3xx, 4xx o 5xx e fixarle.
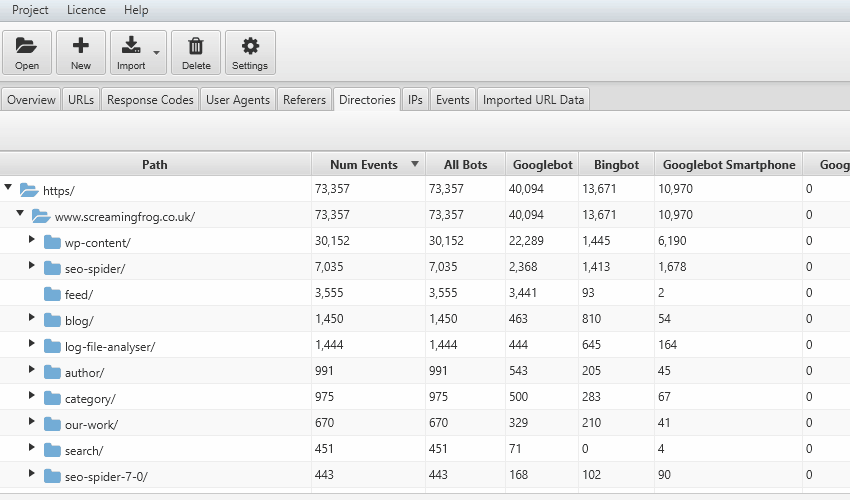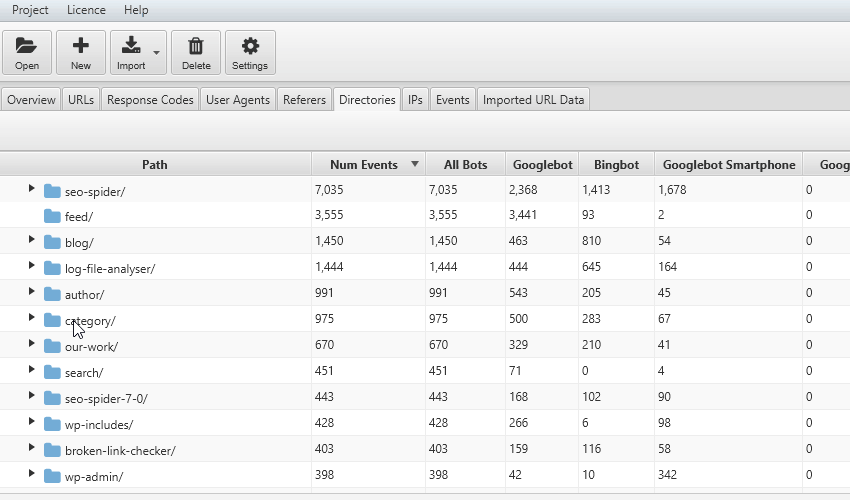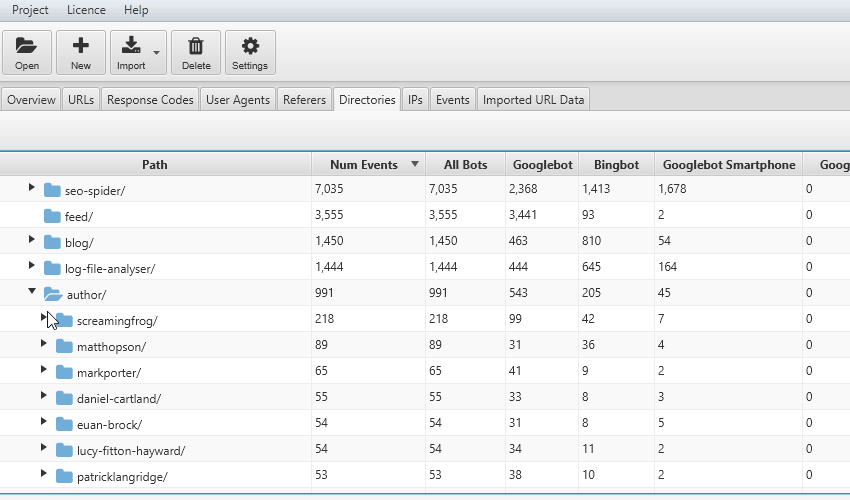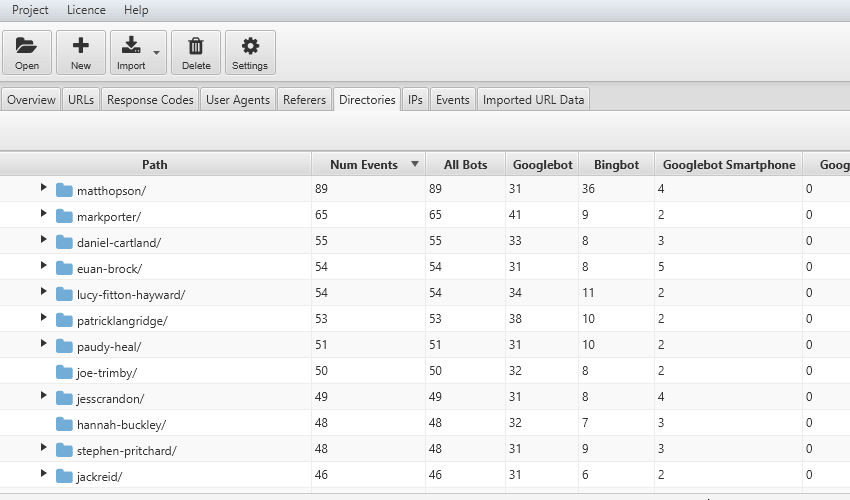
Il file di log non comprende le codifiche per tipologia di contenuto e per questo ci viene in aiuto Log File Analyser che, attraverso il filtro nella tab “URLs” ci permette di analizzare singolarmente gli elementi HTML, Javascript, CSS,Immagini, Pdf, Flash o altri formati. Questa analisi deframmentata per contenuti ci permette di comprendere quanto tempo il Bot sta utilizzando per analizzare ogni tipologia di elemento nel nostro sito web.
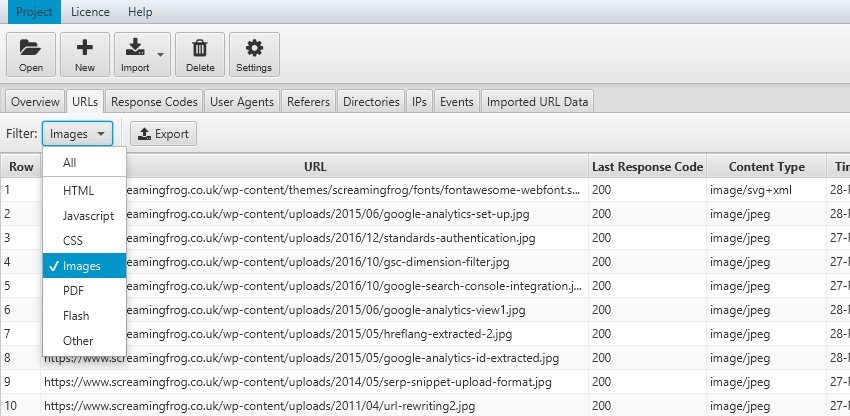
Analizzare la frequenza di scansione di ogni singolo User-Agent è indispensabile se abbiamo siti che vogliono imporsi su mercati internazionali. Sicuramente Google, con il suo GoogleBot, rimane imprescindibile perché copre oltre il 95% delle ricerche mondiali, ma trovare spazio sugli altri motori di ricerca ci permetterà di essere più autorevoli e capillari nel nostro posizionamento.
Essere presenti sulla maggior parte dei motori di ricerca diventa assolutamente propedeutico per colpire specifiche aree geografiche, ad esempio se pensiamo al mercato russo dovremo tenere in considerazione Yandex, per quello asiatico Baidu o americano Bing.
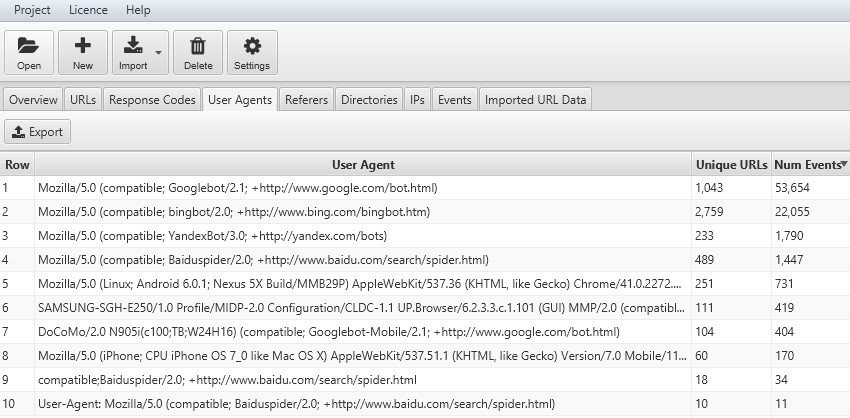
Conoscere la frequenza di scansione del nostro sito web per giorno, settimana o mese ci permette di conoscere approsimativamente quanti URLs unici vengono scansionati al giorno e quanti giorni serviranno allo Spider per fare il “re-crawling” tutti i nostri elementi web. Questo indicatore ci permette di capire se stiamo andando verso la corretta direzione. Riuscire ad aumentare il numero di URLs giornalieri presi in considerazione dai BOT (numero eventi) risolvendo le criticità (response code 3xx, 4xx, 5xx) sarà il nostro obiettivo per risparmiare il Crawling Budget del motore di ricerca ed aumentare l’indicizzazione del nostro sito web con relativo miglioramento potenziale del posizionamento.
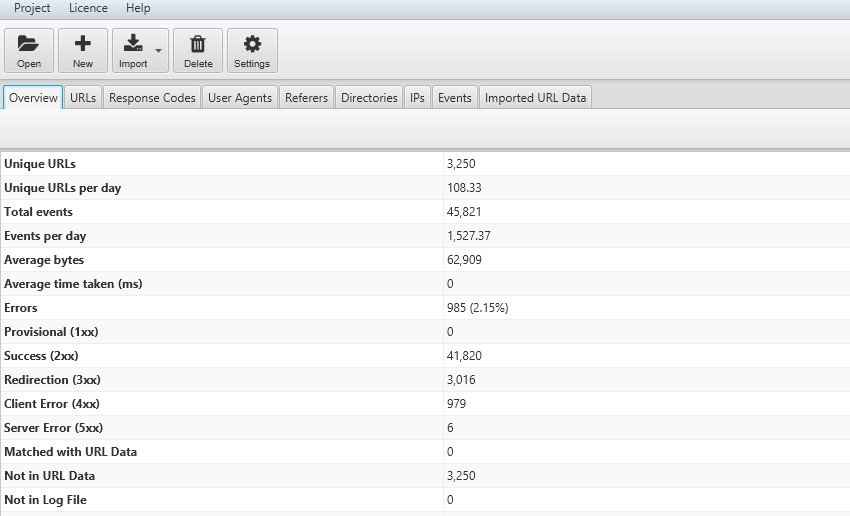
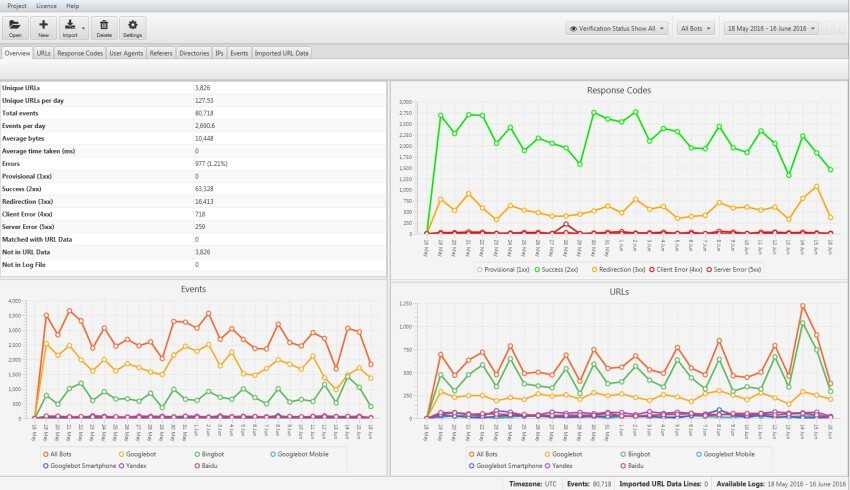
Questi grafici ci permettono di analizzare il trend generale o un particolare problema in termini di URLs restringendo il campo in base all'intervallo di tempo prestabilito.
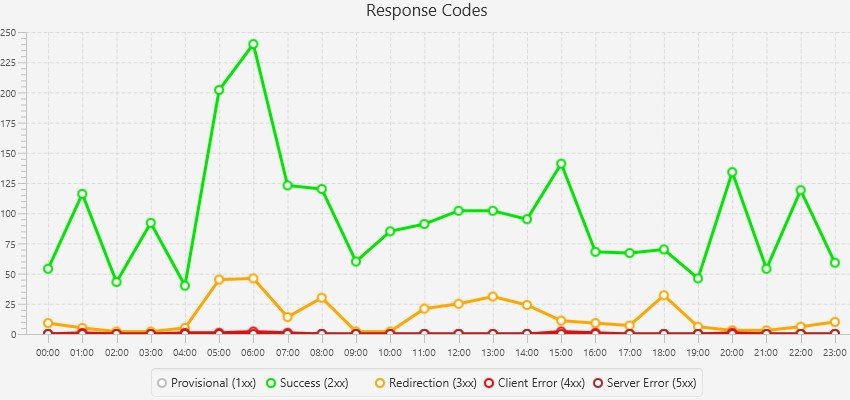
Log File Analyser ci viene in soccorso nelle nostre analisi con la funzione “Last Response Code” che rappresenta l'esperienza in cui si è imbattuto il Bot durante l’ultima scansione. Utilizzando il filtro potremo scoprire eventuali “client error” con errore 4xx che potrebbero essere rappresentati da link errati oppure criticità del server con errori 5xx. Grazie a questa metrica sintetica, ma significativa, riusciremo ad emulare una delle funzioni della Search Console di Google espandendola a tutti i BOT con enorme risparmio di tempo e ottenendo molte più informazioni.
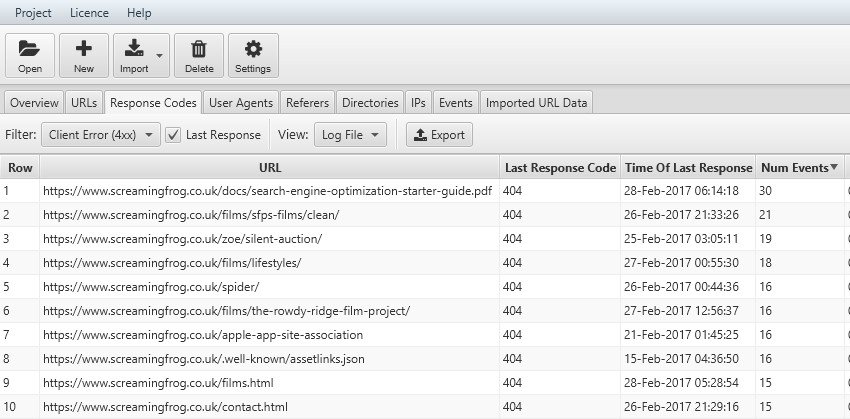
Log File Analyser raggruppa gli errori in base allo "status code" utilizzando i codici 1xx, 2xx, 3xx, 4xx, 5xx per permettere un confronto fra l'ultima scansione ed eventuale incoerenza con dati ottenuti nell’intervallo di tempo prescelto. Questo filtro permette di verificare eventuali collegamenti rotti che sono stati sistemati o errori di server ad intermittenza che devono portarci ad un’analisi più approfondita.
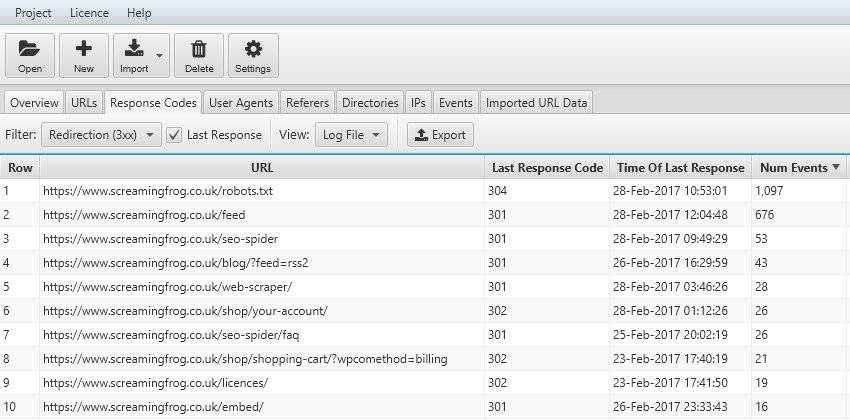
Log File Analyser ci permette di tenere sotto controllo gli elementi richiesti dallo Spider che hanno avuto come risposta un re-indirizzamento verso una nuova pagina. Questa funzionalità ci permette di constatare se i 301 o 302 sono settati correttamente e se, nel tempo, lo spider assuma direttamente il nuovo Url nel suo database o continui a ricercare la vecchia risorsa che aveva già inserito nel suo database (situazione normale dopo una migrazione di un sito web). Anche in questo caso è utile spuntare “last response”.
Log File Analyser ci permette con la tab “IP” di conoscere velocemente se un BOT è reale o un’emulazione di crawling (ad esempio le scansioni fatte con Screaming Frog o altri) usando comparazioni fra User- Agent ma non verificati. Questa funzionalità risulta molto utile nel caso di un “bombardamento” di “crawling” del sito da parte di agenzie concorrenti o spam permettendoci di alzare un muro inibendo gli IP intercettati attraverso il file robots o con l’HTAccess.
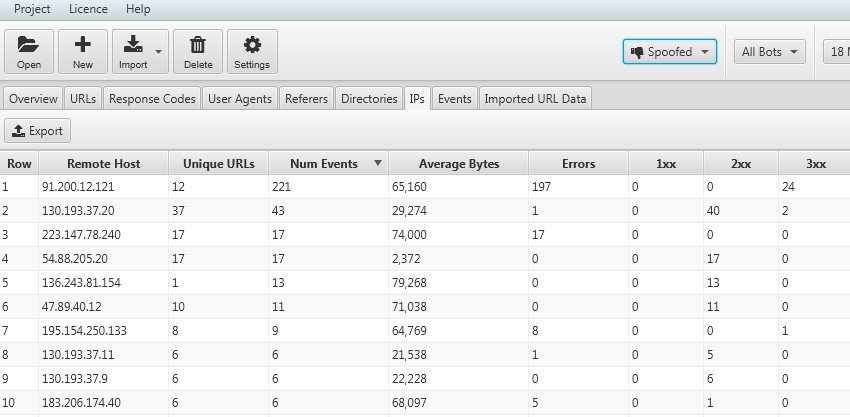
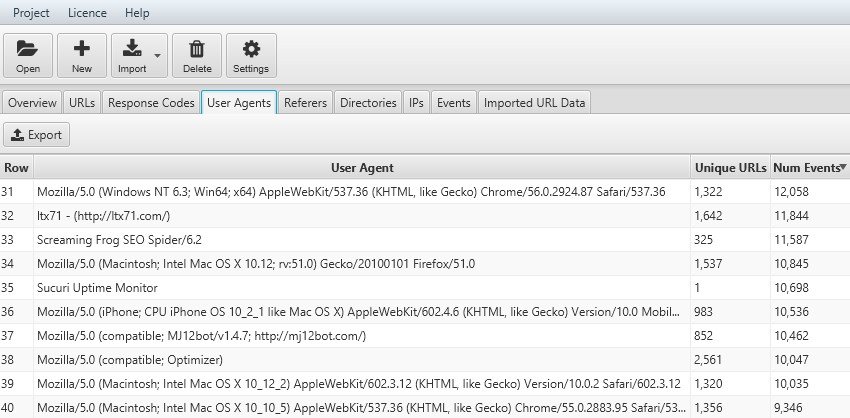
Grazie al filtro “verified” sarà possibile garantire e “matchare” l’IP dei singoli Bot cosicchè sarà possibile analizzare i siti web che propongono contenuti diversificati in base alla alla geolocalizzazione
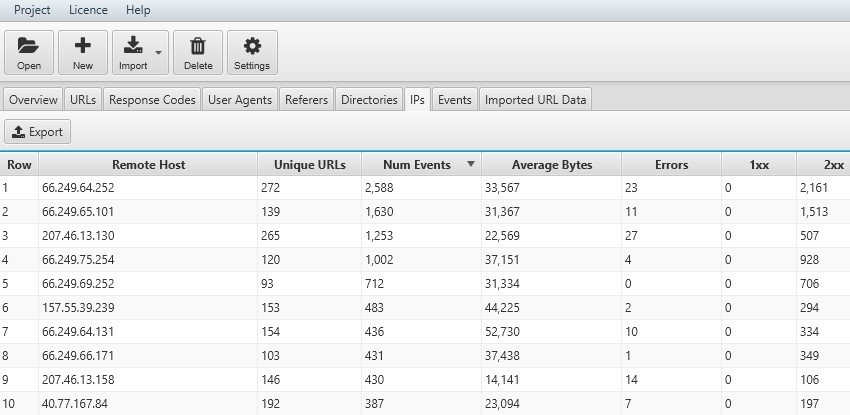
Come abbiamo capito il “Crawling Budget” del BOT viene influenzato dal tempo di download (response time) dei nostri elementi che il Motore di Ricerca investe durante la sua scansione. Analizzando la colonna “Average Bytes” della tab “URLs” avremo a disposizione la lista delle pagine che richiedono maggiori risorse e necessitano di essere ottimizzate per non alimentare delle "waste area" che potrebbero penalizzarci in ottica posizionamento in Serp.
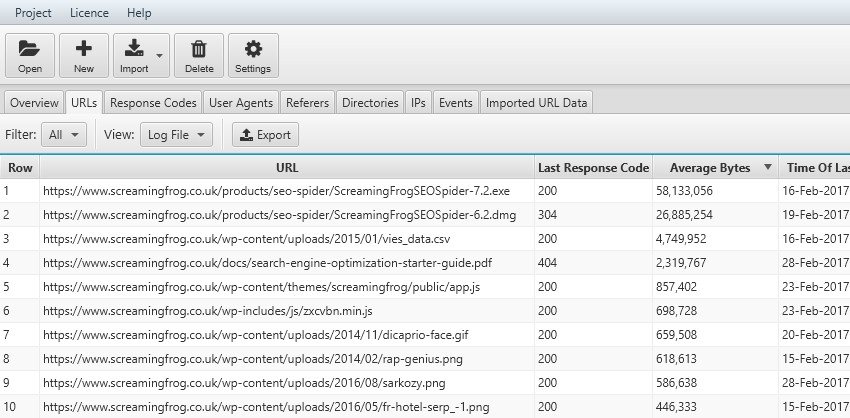
Un ”Average Response Time” troppo elevato impatterà negativamente sul Crawling Budget. Questo dato viene espresso in millisecondi.
Utilizzando la tab URLs e verificando la colonna “Average Response Time” avremo a disposizione una lista di pagine che potrebbero essere ottimizzate per salvare il crawling budget e allegerire il tempo di download delle risorse da parte del Motore di Ricerca.
Se, ad esempio, le pagine che occupano maggiormente il “Crawling Budget” hanno uno status code 500 dovremo investigare sulla risposta del server e sentire il sistemista per una soluzione. Se avessimo un aumento dei "client error" con errore 404 dovremo controllare i nostri link o collegamenti da siti esterni per fixare questa criticità.
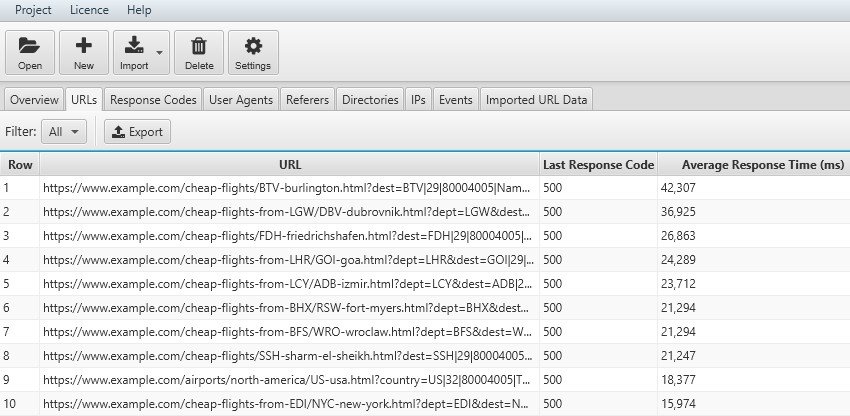
Una delle attività più significative nell’analisi con File Log Analyser è quella di riuscire a “matchare” la nostra sitemap (funzione “import a crawl” - “import a Url”) e il file di Log per scoprire se ci siano degli urls che non vengono “crawlerati” (esempio bloccati da file robots o per la struttura del sito web) o pagine che non riescono ad essere identificate dal Bot per esempio per la mancanza di collegamenti interni.
Attraverso la funzione “Imported Url data” sarà possibile, attraverso un “Drag & Drop”, importare gli URLs. Dopodiché utilizzando i filtri potremo ottenere i seguenti risultati:
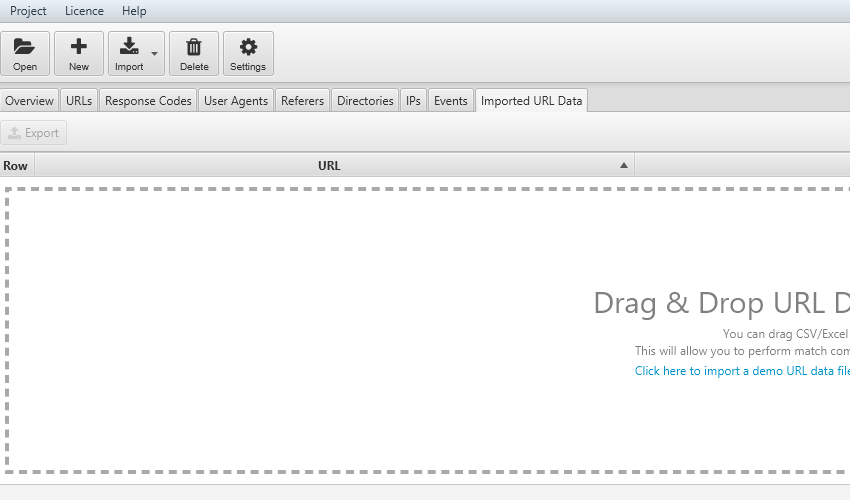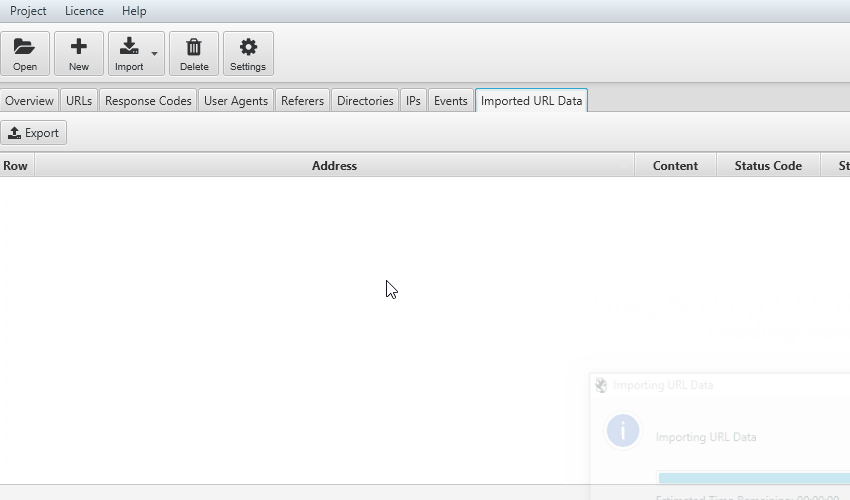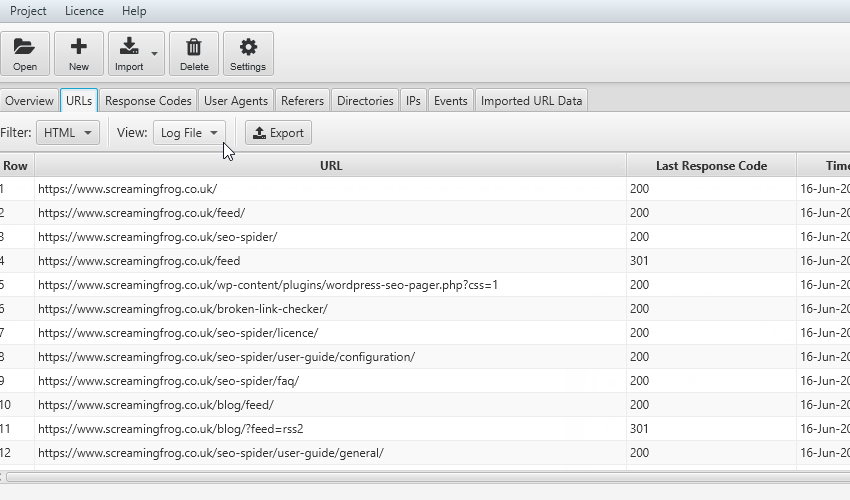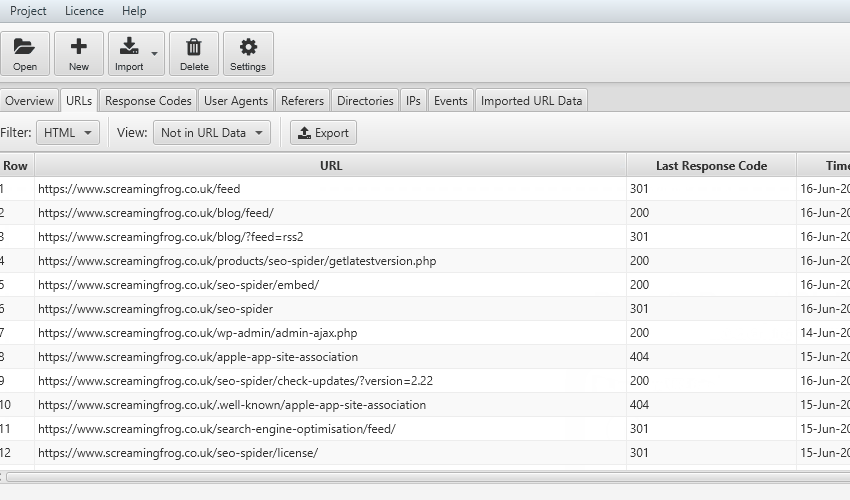
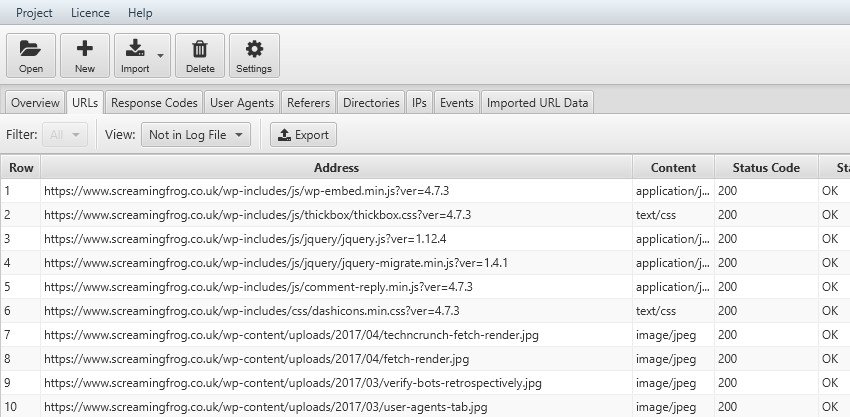
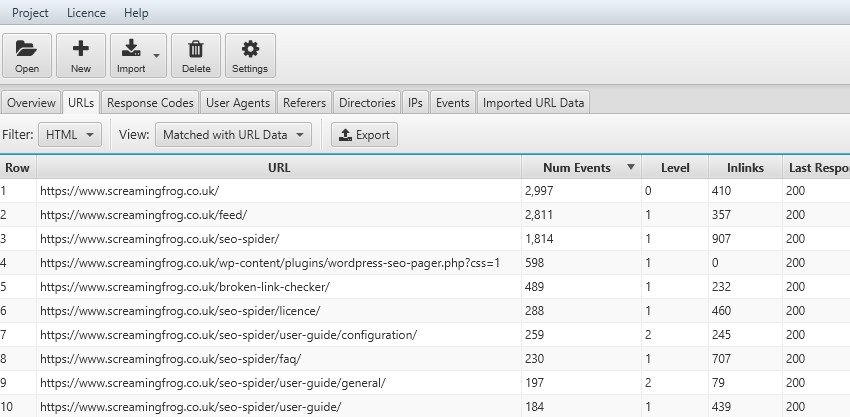
Il confronto fra gli URLs importati e i file di log è importante anche per valutare l’impatto delle direttive impostate a lato codice (tag canonical, no index o altro) rispetto al comportamento del BOT.
Se ad esempio, dopo una migrazione, volessimo impostare delle direttive “no index” a delle pagine ancora presenti ma che vogliamo declassare nel tempo o volessimo bloccare delle risorse con il file robots potrebbe essere uno strumento di analisi molto utile nell'analisi comportamentali del Motore di Ricerca.
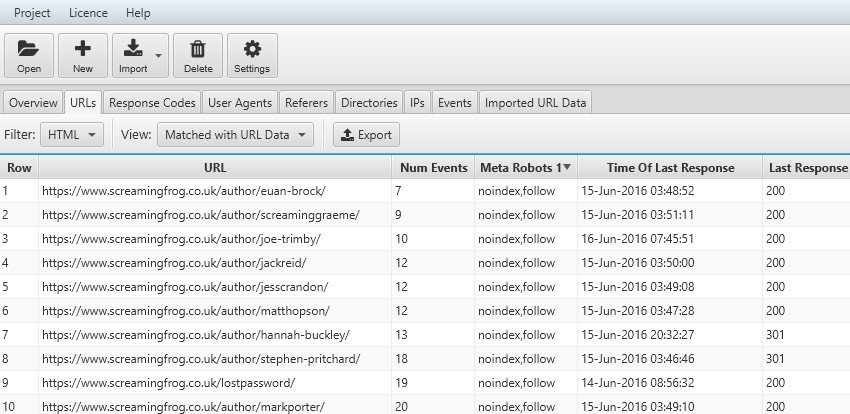
Uno degli elementi più rilevanti nel ranking dei motori di ricerca è il numero di collegamenti alle nostre risorse da link esterni (backlinks). La nostra analisi con Log File Analyser potrebbe partire inserendo una lista delle nostre pagine più importanti (top pages) e confrontare la frequenza di scansione con il valore dei link in entrata magari collegando strumenti come Majestic Seo. Questo tool ci fornirà oltre che il numero assoluto di collegamenti esterni anche dati molto interessanti sul valore intrinseco dei link (TrustFlow e CitationFlow). L’azione successiva potrebbe essere quella di esportare i dati e confrontare la correlazione fra il ranking delle pagine e i benefici ottenutio mediante i collegamenti esterni.
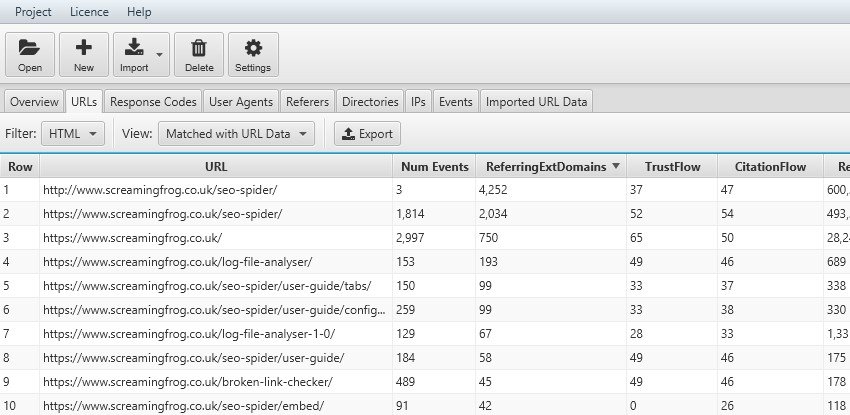
Se abbiamo deciso di bloccare delle “directives” o pagine ai BOT dobbiamo verificare che queste indicazioni vengano seguite e rispettate.
Nel caso meno grave possiamo verificare che le pagine “canonicalized” non vengano crawlerate o, al massimo, che il bot non dia priorità a questi elementi sempre nell’ottica di salvaguardare il Crawling Budget del Motore di Ricerca. L’idea potrebbe essere quella di fare una scansione con Screaming Frog, esportare gli elementi con tag “canonicalized” o “no-index” e matchare i dati con il file di log magari in un foglio di calcolo.
In questa guida abbiamo capito le potenzialità di Log File Analyser e la necessità di conoscere approfonditamente il comportamento dello Spider durante la sua scansione sul nostro sito web. Sicuramente ogni funzionalità di questo strumento merita un'ulteriore approfondimento per ottenere dati sempre più granulari e precisi. Il nostro intento era fornirvi degli spunti e delle idee di analisi ora tocca a voi. Scrivete qui sotto altri suggerimenti e sarà un piacere integrarli nella nostra mini guida.
Credits: La guida è stata tradotta ed integrata da quella ufficiale di Screaming Frog nella sezioneLog File Analyser. Le immagini sono di proprietà della società Screaming Frog. Download Log File Analyser.


SONDRIO (sede operativa)
Via Stelvio, 24 - 23020 Poggiridenti (SO)
MILANO (sede legale)
Corso Europa, 10 - 20122 Milano (MI)

Webtek S.p.A. SB - P.IVA: 00952780146 - REA MI-2109845 - Cap. Soc.: € 50.000,00 - Copyright 2025