Hai una richiesta specifica? Ti serve uno dei nostri servizi? Vuoi semplicemente conoscerci?
Qualsiasi sia la tua necessità, contattaci e saremo lieti di prendere in carico la tua richiesta.




Prima di iniziare l’attività di “Crawling” è consigliabile andare a configurare il comportamento dello Spider per gestire, secondo le nostre necessità, la scansione verso il nostro sito in esame.
Configuration → Spider
In questo modo potremo scegliere quali siano gli elementi che vogliamo far scansionare a Screaming Frog. Fra tutti gli elementi a disposizione possiamo scegliere fra:
SEO TIPS: controllando le immagini e il “path relativo” possiamo decidere di modificarne il nome e migliorare la percezione di GoogleBot e degli altri Spider inserendo delle parole chiavi nelle “folder” e nel nome immagine per orientare al massimo lo Spider alla tematicità del nostro dominio. Questa funzione è fondamentale nel caso di Migrazione” del sito internet per non generare troppi “404” e predisporre eventuali redirect prima di andare online con la nuova versione.
Questo è un esempio classico di gestione delle immagini con nomi generalisti. Per aiutare lo Spider e il visitatore finale vediamo come potrebbe essere migliorato. Presupponiamo di considerare un’immagine legata al nostro sito che vende servizi di Web Marketing:
www.nomedominio.com/uploads/img/gallery/servizi-seo.jpg
Già modificando solamente il nome immagine facciamo subito capire a che cosa si riferisca l’immagine ma potremo anche spingerci oltre e catalogare in modo appropriato tutto il path relativo all’immagine:
www.nomedominio.com/servizi/web-marketing/gallery/servizi-seo.jpg
Grazie a questo intervento abbiamo dato molti più dettagli allo Spider e categorizzato, in modo appropriato, tutto l’URl associando il tema all’immagine, la categoria ed inserendo, senza sovra-ottimizzare le parole chiavi legate al nostro “core business”.
SEO TIPS: il flash, tipologia di programmazione molto in voga fino a circa 5 anni fa è sconsigliabili perchè non viene digerita dallo Spider dei motori di ricerca. Se vengono presentati dei risultati in “flash” si consiglia di sostituirli con Javascript.
SEO TIPS: il consiglio è quello di inserire il tag “No Follow” verso tutti i link che puntano a fonti esterne per non disperdere il proprio “Juice rank”. Infatti per ogni link in uscita, senza questo tag, il nostro “trust” viene suddiviso, anche se in minima parte, con la risorsa collegata.
Per eseguire un “crawling” di una singola e specifica cartella (sub-folder) sarà sufficiente inserire l’URl esatto e premere “start” dalla piattaforma, senza ulteriori modifiche, sulle impostazioni di default. Nel caso in cui le impostazioni siano state modificate precedentemente sarà sufficiente andare seguire questi semplici step:
MENU → FILE → DEFAULT CONFIGURATION → CLEAR DEFAULT CONFIGURATION
SEO TIPS: il tag “Canonical” è uno strumento molto importante per evitare contenuti duplicati e orientare lo Spider. Un uso comune si presenta quando due pagine, che presentano URLs differenti, contengono lo stesso contenuto.
Un esempio classico è quello degli e-commerce nei quali una “pagina prodotto” può essere raggiunta da più fonti:
| PRODOTTO FINALE | RAGGIUNGIBILE DA | URL |
| Maglia corta bianca Adidas | sezione Brand | dominio.com/Adidas/maglia-corta-bianca |
| Maglia corta bianca Adidas | sezione Abbigliamento Uomo | dominio.com/abbigliamento-uomo/maglia-corta-bianca |
In questo caso il prodotto finale “Maglia Corta Bianca Adidas” è raggiungibile dalla sezione “brand di Adidas” e dalla sezione “Abbigliamento Uomo” generando due URLs diversi ma con lo stesso contenuto (duplicato per il motore di ricerca).
Per ovviare a questa situazione sarebbe ideale inserire il tag “Canonical”, nel codice html questo tag scegliendo quale sia la pagina da indicizzare e quale da de-indicizzare perchè secondaria. Se decidiamo che, nel nostro esempio, la pagina abbigliamento uomo è principale avremo il seguente codice:
| URL FINALE PRODOTTO | TAG CANONICAL |
| dominio.com/Adidas/maglia-corta-bianca | <link rel="canonical" href="www.dominio.com/abbigliamento-uomo/maglia-corta-bianca" /> |
| dominio.com/abbigliamento-uomo/maglia-corta-bianca | <link rel="canonical" href="www.dominio.com/abbigliamento-uomo/maglia-corta-bianca" /> |
In questo esempio avremo detto allo Spider che la pagina “dominio.com/Adidas/maglia-corta-bianca” è stata “canonicalizzata” verso la pagina “dominio.com/abbigliamento-uomo/maglia-corta-bianca”.
SEO TIPS: questo Tag è molto importante soprattutto nella gestione di blog/news per definire le pagine di “categorie” o nel caso di un articolo che presenta più parti in pagine diverse per far capire allo Spider la presenza di un “listato” di URLs concatenati.
Es. un articolo è stato suddiviso in 3 parti e pubblicato su 3 differenti URLs:
| PAGINA | URL PAGINA | TAG NEXT-PREV |
| I° Parte | dominio.com/news/?pag=1 | <link rel="next" href="dominio.com/news/?pag=2"> |
| II° Parte | dominio.com/news/?pag=2 | <link rel="prev" href="dominio.com/news/?pag=1"> <link rel="next" href="dominio.com/news/?pag=3"> |
| III° Parte | dominio.com/news/?pag=3 | <link rel="prev" href="dominio.com/news/?pag=2"> |
SEO TIPS: il tag Hreflang è necessario su tutti i siti multilingua per orientare lo Spider verso i contenuti tradotti. Questo permette di far conoscere al Bot tutte le versioni dello stesso contenuto senza rischiare “duplicazioni”:
| URL | LINGUA | TAG |
| dominio.com/it | italiano | <link rel="alternate" href="dominio.com/it" hreflang="it" /> <link rel="alternate" href="dominio.com/en" hreflang="en" /> |
| dominio.com/en | inglese | <link rel="alternate" href="dominio.com/en" hreflang="en" /> <link rel="alternate" href="dominio.com/it" hreflang="it" /> |
Come si vede in entrambe le pagine verrà inserito lo stesso codice. Analizziamo il codice della pagina italiana:
In questo caso stiamo dicendo allo Spider che se un visitatore parla “italiano” dovrà essere inviato alla versione “it” altrimenti se parla inglese alla versione “en”. Ma cosa succede ad un utente che non parla (es. il browser è impostato sulla lingua tedesca) né italiano che tedesco? In questo caso dovremo utilizzare una versione di default che comprenda tutti gli utenti che non parlano italiano o inglese. Se scegliessimo la lingua inglese il nostro tag Hreflang sarebbe così gestito:
| URL | LINGUA | TAG |
| dominio.com/it | italiano | <link rel="alternate" href="dominio.com/it" hreflang="it" /> <link rel="alternate" href="dominio.com/en" hreflang="x-default" /> |
| dominio.com/en | inglese | <link rel="alternate" href="dominio.com/en" hreflang="x-default" /> <link rel="alternate" href="dominio.com/it" hreflang="it" /> |
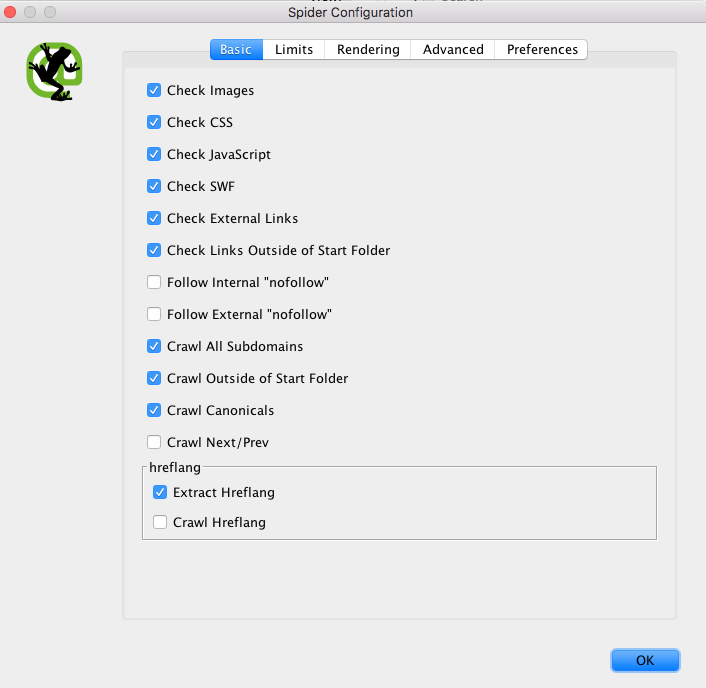
Nota Bene: se decidiamo di fare un “crawler” inserendo tutti gli elementi qui indicati potrebbe risultare molto pesante e richiederà uno sforzo di memoria molto elevato oltre ad un tempo di scansione allungato.

SONDRIO (sede operativa)
Via Stelvio, 24 - 23020 Poggiridenti (SO)
MILANO (sede legale)
Corso Europa, 10 - 20122 Milano (MI)

Webtek S.p.A. SB - P.IVA: 00952780146 - REA MI-2109845 - Cap. Soc.: € 50.000,00 - Copyright 2025